


Building a Basic Recommendation Engine: No Machine Learning Knowledge Required!


Recommendation systems have become an integral and indispensable part of our lives. These intelligent algorithms are pivotal in shaping our online experiences, influencing the content we consume, the products we buy, and the services we explore. Whether we are streaming content on platforms like Netflix, discovering new music on Spotify, or shopping online, recommendation systems are quietly working behind the scenes to personalize and enhance our interactions. The unique element of these recommendation systems is their ability to understand and predict our preferences based on historical behaviour and user patterns. By analyzing our past choices, these systems curate tailored suggestions, saving us time and effort while introducing us to content/products that align with our interests. This enhances user satisfaction and fosters discovery, introducing us to new and relevant offerings that we might not have encountered otherwise.
At a high level, developers understand that these algorithms are powered by machine learning and deep learning systems (interchangeably called neural networks), but what if I tell you there is a way to build a recommendation engine without going through the pain of deploying your neural net or machine learning model?
This question is specifically relevant in the context of early and mid-stage startups because they don't have tons of structured data to train their models. And as we already know, most machine learning models will not give accurate predictions without proper training data.
I recently built and deployed a basic recommendation engine for a voice-first social network, which led to a 40% jump in our key metrics. At the time of writing this blog, the system is generating more than 30 million recommendations per month. Even though this recommendation system was built for a social network, you can apply the basic architecture to any use case, such as product recommendations, music recommendations, content recommendations on text and video platforms, or anything else. Let me start by describing the problem statement.
Problem statement from the engineering perspective
I had an extensive product requirement document and subsequent engineering requirementsdocument because we were building the recommendation system for a product that is already used by thousands of users daily. But to keep this blog short and on point, I will write only the high-level requirements and then discuss the solution of the same. If you are building a recommendation system for your product (simple or neural net-based) and are stuck somewhere, please feel free to contact me on Twitter or Linkedin, and I will be more than happy to answer your questions.
At a high level, we had the following requirements from an engineering perspective -
The system should be able to capture a user's interests in the form of keywords. The system should also be able to classify the level of interest a user has with specific keywords.
The system should be able to capture a user's interest in other users. It should be able to classify the level of interest a user has in content created by another user.
The system should be able to generate high-quality recommendations based on a user's interests.
The system should be able to ensure that the recommendations already viewed/rejected by the user shouldn't re-appear again for X number of days.
The system should have logic to ensure that the posts from the same creators aren't grouped on the same page. The system should try its best to ensure that if a user consumes ten posts (our page size), all of those should be from different creators.
The system should be fast. Less than 150 milliseconds of P99 latency.
All the other non-functional requirements, such as high availability, scalability, security, reliability, maintainability, etc, should be fulfilled.
Again, this is a highly oversimplified list of problem statements. In reality, the documents were 3000+ words long as they also covered a lot of edge cases and corner cases that can arise while integrating this recommendation engine into our existing systems. Let's move on to the solution.
Solution - High-level working of the recommendation engine
I will discuss the solutions to the problem one by one and then will describe the overall working of the entire system.
Our first problem is capturing the user's interests and defining their interest level with a specific interest.
For this, we created something called a social graph. To put it simply, a social graph stores the relationships and connections between different entities in a social network. These entities can be different users or a relationship of users with a specific interest. Social graphs are a powerful way to understand and structure the relationships within a particular system. For the sake of brevity, I will not explain the social graph in detail, but I will recommend you google it and learn more about it. Following is a simplified version of the social graph I built for our recommendation engine.
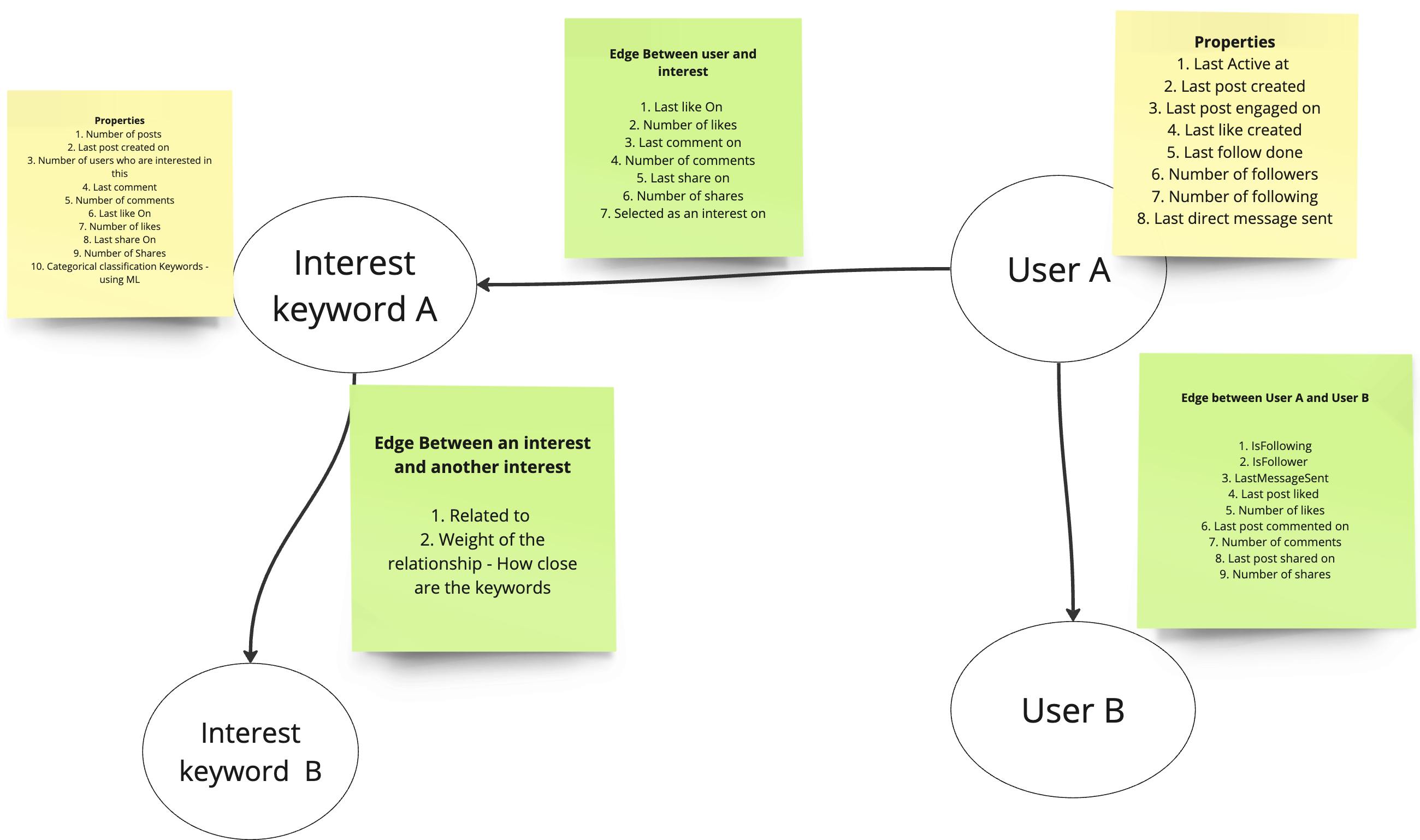
As you can see from the above image, we are storing a lot of information, such as the number of interactions (likes, comments, shares) and recency of these interactions (when they happened last) as relationship data between two users as well between a user and an interest. We are even storing the relationship between two different interest keywords. I used Amazon Neptune, a managed graph database by AWS, to store this social graph. You can use any other graph database, such as Neo4j, JanusGraph, ArrangoDB, etc.
These interest keywords are predominantly nouns. There is a system in place that breaks down the contents of a post into these keywords(nouns). It's powered by AWS comprehend a natural-language processing (NLP) service that uses machine learning to break text into entities, keyphrases etc. Again, you can use any managed NLP services (several available) to accomplish the same. You don't need to learn or deploy your own machine-learning models! If you already understand machine learning, then you can go check open-source NLP models as well on Huggingface.
Our second problem is generating high-quality recommendations based on a user's interest.
The following diagram is a simplified high-level representation of how the system works.
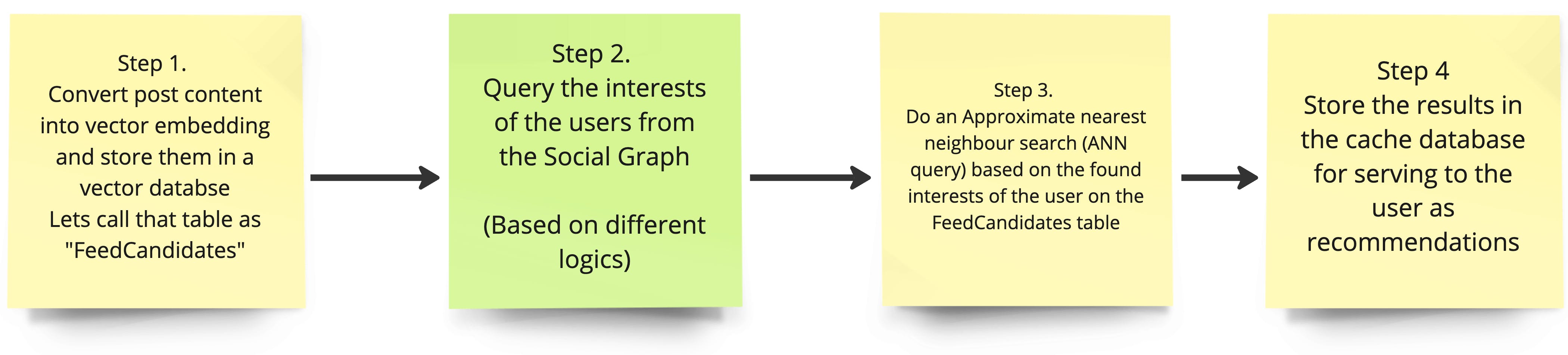
While the above looks easy, there is a lot more going on at each step, and those things have to be carefully thought through and then programmed in order to ensure that the system is performing optimally. Let me explain step by step.
Step 1 - Converting post content into vector embeddings
To generate these recommendations, first, we have to convert the contents of a post into something called - Vector embeddings. With the recent uptick in the branding of LLMs, OpenAI( the makers of ChatGPT) and Vector databases, Vector embeddings are becoming an everyday term. I will not go into the details of what they are and how they work, but I highly recommend reading more about them. But generating viable candidates for a feed also has to account for things like content privacy and moderation (removing profane words, abuses, sexual content, harassment, filtering blocked users, etc).
For generating the vector embeddings, you can use any prominent embedding model such as the OpenAI embedding model, Amazon titan or any open source text embedding model, depending on your use case. We went with Amazon Titan because of its friendly pricing, performance and operational ease.
Step 2 - Query the user's interest
Now, this is where things get interesting. You would want to design the queries based on your specific business needs. For example, we give more weightage to the recency of engagement while querying interests than the number of engagements with a specific keyword or user. We also run multiple parallel queries to find different types of interest of the user - keyword or other user. Since we generate multiple feeds for a single user, we also run some queries promoting a specific topic according to the trend (for example, you will see many Christmas-related posts near Christmas or earthquake-related posts if some earthquake has happened). Needless to say, this topic will only come up in the query results if the user has expressed some interest in them in their journey.
So, choose the logic that suits your business use case and the behaviour that you want to drive and run multiple queries to get a big enough list of all the user's interests.
Step 3 - Do an ANN search based on the interests found
Vector databases are predominantly used for performing a particular type of search called Approximate nearest neighbour search(ANN). Again, the way you categorize various interests and whether you are doing one big ANN search or parallel difference searches should entirely be based on your use case and business requirements. I recommend doing more than cohort-based searches and then ordering the results (we will discuss this later in this blog) for the best end-user experience. What ANN search does, in this case, is find other posts on the platform which are similar (closer) to the interests of the user.
Step 4 - Store the results in a cache database with ordering.
Cache database because one of the problems that we need to solve is speed. We used redis sorted sets for storing the unique IDs of the posts for a specific user. We used redis sorted sets because the order of posts in a user's feed is critical. Also, another problem that you have to solve is that the" system should have logic to ensure that the posts from the same creators aren't grouped on the same page". To avoid repetition of content from the same creator, we have written a simple algorithm which ensures that if a specific creator's post is inserted at any position in a particular user's feed (sorted set), we don't insert another post from the same creator for successive ten positions (we have a page size of 10 while serving the feed to the end user, so we kept it static to avoid complexity).
For deciding the order of a specific recommendation of the user, we factored in the following things -
The strength of the relationship with a specific interest (or another user) for this user: It's determined by an arithmetic formula that takes various data points from the social graph. All of this is engagement data like the timestamp of the last likes created, number of likes created, last comment, etc. User engagement behaviour is the indicator of their interest in something.
The popularity of the post on the platform: To determine this, we have created an algorithm that takes various factors such as engagement, engagement-to-impression ratios, number of unique users who engaged, etc., to generate an engagement score of that post at a platform level.
In some feeds, we prioritize popularity; in others, we prioritize the social graph. But mostly, all of them are a healthy mix of the two.
Working of the system

As you can see from the diagram above, the system has been intentionally kept very simple. Following is how the system works -
When user A creates a post, the post service, after saving that post, triggers a pub/sub event to a queue, which is received by a background service meant for candidate generation. We use Google Pub/Sub for the pub/sub functionality.
This background service receives this asynchronously and performs functionalities discussed earlier - Privacy checks, moderation checks, and keyword generation and then generates the vector embeddings and stores them in the vector database. We are using AstraDB as our vector database (discussed later).
Whenever a user engages (like/comment/share, etc.) after updating our main NoSQL database, the post-service triggers a pub/sub event to the recommendation engine service.
This recommendation engine service updates the graph database and then updates the recommended feed of the user in near real-time by performing the ANN search and updating the Redis database. So, the more users interact, the better the feed keeps getting. There are checks to ensure that the recommendations are not biased towards a specific list of keywords. Those checks are performed while we query the Graph database. This service also updates the engagement score asynchronously. Engagement scores are re-calculated on users viewing the post as well.
Since all of the above steps are performed asynchronously behind the scenes, these computations have no impact on the end-user experience.
The feed is finally served to the end user through a feed service. Since this service just performs a lookup on redis and our main NoSQL database (DyanmoDB), its P99 latency is less than 110 milliseconds. Both these databases return query results in single-digit millisecond latency irrespective of scale.
Tools and technologies used
Some services have been written in Go programming language, while others have been written in NodeJS(with typescript).
We are using AstraDB by Datastax as our vector database. We arrived at this decision after evaluating multiple other databases, such as pinecone, milvus and weaviate. Apart from its excellent query and indexing capabilities on vector and other data types, it offers a pocket-friendly serverless pricing plan. It runs on top of a Cassandra engine, which we use as a database in several other features on our platform, and it gives a CQL query interface, which is very developer-friendly. I highly recommend trying it for your vector use cases.
We use Google pub/sub for our asynchronous communication because, at our current scale (few lakh total users, few thousand daily active users), it's highly cost-effective. I have run it at a scale of a few lakh users with thousands of events per second. It works well, and it's effortless to use and extend.
Redis - Speed, simplicity and powerful data structure. I don't think I need to discuss why redis in 2024.
DynamoDB - Again, it is highly scalable and easy to use, and we run it in the serverless mode where, despite hundreds of thousands of queries per minute, our total bill is quite low. It also offers very powerful indexing capabilities and single-digit millisecond latency in reads and writes.
Problems to be solved in the future
As you can imagine, this same setup can be tweaked to build a basic recommendation engine for any use case. But, since ours is a social network, we will require some tweaks down the line to make this system more efficient.
Machine learning/ Deep learning algorithms will be needed at the social graph level to predict the keywords and users most relevant for the user. Currently, the data set is too small to predict anything accurately as it is a very new product. However, as the data grows, we will need to replace the current simple queries and formulas with the output of machine learning algorithms.
Relationships between various keywords and users must be fine-tuned and made more granular. They are at a very high level right now. But they will need to be deeper. We will need to explore the second and third-degree relationships in our graph to refine the recommendations first.
We are not doing any fine-tuning in our embedding models right now. We will need to do that in the near future.
Ending note
I hope you found this blog helpful. If you have any questions, doubts or suggestions, please feel free to contact me on Twitter, Linkedin or Instagram. Do share this article with your friends and colleagues.
The Startup Developer series
If you are reading this, thanks for completing this post. This blog post is a part of my ongoing series called "The Startup Developer". This entire blog series is dedicated to all the "startup developers" out there. The blog series aims to share the learning, hacks, tips and tricks that have worked for me. If I can save you even a few hours per week, I will count it as a win.
Following are the posts in this series in order -